学习 transformers 的第一步,往往是几句简单的代码
from transformers import pipeline
classifier = pipeline("sentiment-analysis")
classifier("We are very happy to show you the 🤗 Transformers library.")
"""
[{'label': 'POSITIVE', 'score': 0.9998}]
"""
但等你配好环境然后简单运行一下,你就会发现一点也不简单!

直接报错ConnectionError,一查原来是被huggingface被和谐了啊,科学上网都救不了,然后报错里提到是:
https://huggingface.co/distilbert/distilbert-base-uncased-finetuned-sst-2-english
连不上。
但方法肯定是有的,网上大多数方法都是照搬
https://hf-mirror.com/
的主页,又是改环境变量又是下载下载工具的,给的例子也一点不具体。实际根本不好用,命令行配置太多,然后名字有太长,实际上它的作用也就是把
https://hf-mirror.com/distilbert/distilbert-base-uncased-finetuned-sst-2-english
下面所有的东西都下下来。。。 这些东西并非全都用得到吧,下下来是需要好很长时间的吧,那假设我只是使用pytorch而已的话,需要下哪些东西呢?(附注:你当然可以通过代码或者命令行指定匹配规则进行过滤来指定下什么东西,但是这样看着太冗长,感觉不如自己手下来的方便直观)
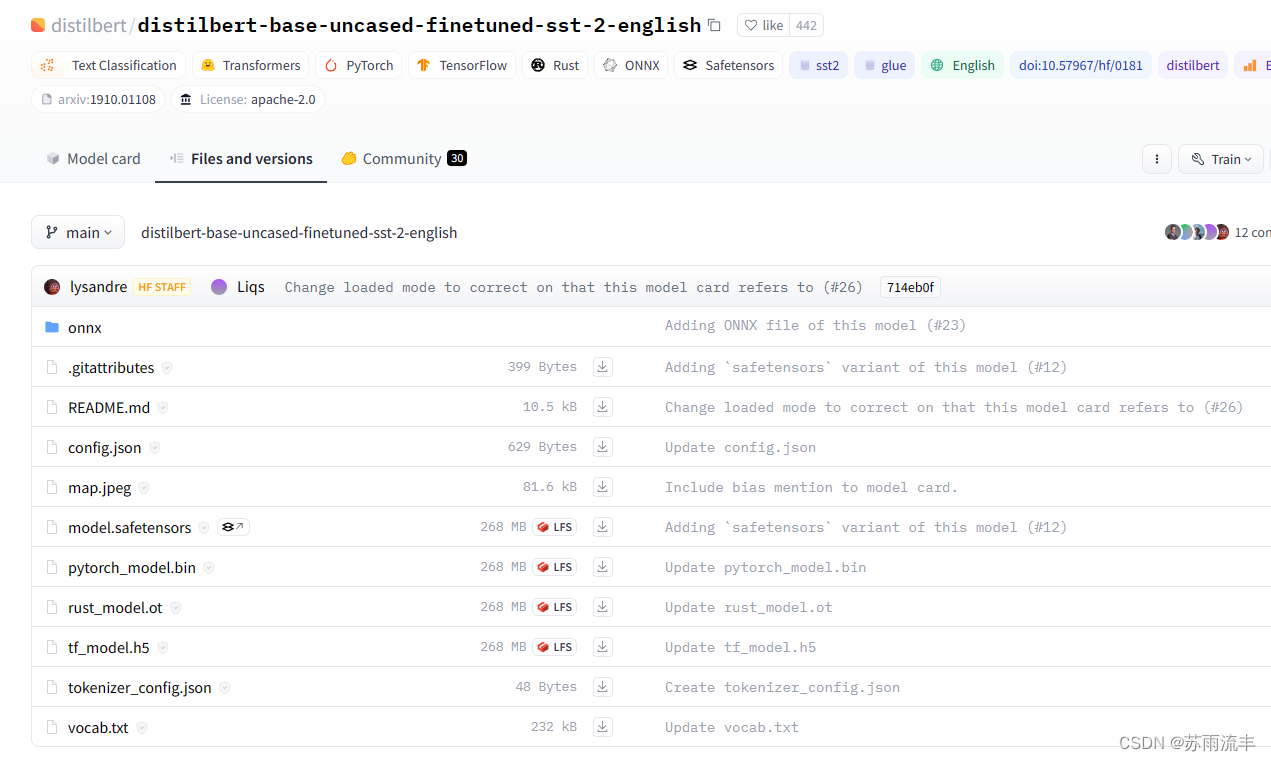
经过各种查阅和总结试错,假如你只是想使用pytorch下的模型,你只需要下载:
pytorch_model.bin
config.json
tokenizer_config.json
vocab.txt
即可,那么好,接下来要怎么加载这个模型并使用它呢?这个问题得到了很快的解决,通过报错的提示,还有命名,大概就能猜出来。一般来说,先指定根路径,也就是刚刚下载好的那4个文件的路径,然后指定模型基类和tokenizer基类,最后才可以顺利调用pipleline.总结如下:
import transformers
from transformers import pipeline, DistilBertForSequenceClassification, DistilBertTokenizer
# 1. 手动下载好上面说的四个文件并存到指定目录
bert_path = "D:/datasets/huggingface/models/distilbert-base-uncased-finetuned-sst-2-english"
# 2. 使用正确的基类(鸡肋)来加载 model tokenizer
# (DistilBertTokenizer, DistilBertForSequenceClassification)也都是尝试出来的
tokenizer = DistilBertTokenizer.from_pretrained(bert_path)
model = DistilBertForSequenceClassification.from_pretrained(bert_path)
classifier = pipeline("sentiment-analysis", model=model, tokenizer=tokenizer)
随后,就可以进行玩耍了
比如这里我给了一个长长的句子,大概描述了我刚刚踩的坑(你也知道这是negative啊)
classifier("It is a bad experience when I try to access hugging face, "+
"I have to downald them in mirror website and analyze which files shoud I downald!")
[{'label': 'NEGATIVE', 'score': 0.999805748462677}]
再来个句子,带点转折意味
classifier("However, method always exists, although it takes too much time!")
[{'label': 'POSITIVE', 'score': 0.9861053824424744}]
再来个,断章取义取自不要断章取义!
classifier("although it takes too much time!")
[{'label': 'NEGATIVE', 'score': 0.9921171069145203}]
看得出来还是挺准的