文章目录
1 知识蒸馏(knowledge)背景
在训练模型时,我们通常采用复杂模型或者Ensemble方式来获取最好的结果,导致参数冗余严重,像BERT里有3亿参数。因此在前向预测时,需要对模型进行复杂的计算(或多个模型加权),导致工程性能较差。因此需要把复杂模型或者多个模型Ensemble(Teacher)学到的知识 迁移到另一个轻量级模型( Student )上叫知识蒸馏。使模型变轻量的同时(方便部署),尽量不损失性能。<Hinton, NIPS 2014workshop https://arxiv.org/pdf/1503.02531.pdf>
知识蒸馏是一种模型压缩常见方法,用于模型压缩指的是在teacher-student框架中,将复杂、学习能力强的网络学到的特征表示“知识蒸馏”出来,传递给参数量小、学习能力弱的网络。从而我们会得到一个速度快,能力强的网络,因此这是一个概念上的模型压缩方案。
从另一个角度来说,蒸馏可以使得student学习到teacher中更加软化的知识,这里面包含了类别间的信息,这是传统one-hot label中所没有的。由于蒸馏中软化标签的本质,因此蒸馏也可以被认为是一种正则化的策略。

2 知识蒸馏原理
2.1 概念
蒸馏的核心思想在于好模型的目标不是拟合训练数据,而是学习如何泛化到新的数据。所以蒸馏的目标是让学生模型学习到教师模型的泛化能力,理论上得到的结果会比单纯拟合训练数据的学生模型要好。
在蒸馏的过程中,我们将原始大模型称为教师模型(teacher),新的小模型称为学生模型(student),训练集中的标签称为hard label,教师模型预测的概率输出为soft label,temperature(T)是用来调整soft label的超参数。
2.2 如何蒸馏
上面提到了,蒸馏就是为了提升学生模型的泛化能力。
举个例子,在一个二分类任务中,教师模型的输出本该是0-1分类结果,但是这样的输出给student模型学习的话和原先的hard label没有什么区别,所以取出teacher model的概率输出q,并通过一个参数T进行平滑,是的TM(teacher model)的softmax变为:
q
i
=
exp
(
z
i
/
T
)
∑
j
exp
(
z
j
/
T
)
q_{i}=\frac{\exp \left(z_{i} / T\right)}{\sum_{j} \exp \left(z_{j} / T\right)}
qi=∑jexp(zj/T)exp(zi/T)
有了教师模型的输出后,学生模型的目标就是尽可能拟合教师模型的输出,新loss函数就变成了:
L
=
(
1
−
α
)
C
E
(
y
,
p
)
+
α
C
E
(
q
,
p
)
⋅
T
2
L=(1-\alpha) C E(y, p)+\alpha C E(q, p) \cdot T^{2}
L=(1−α)CE(y,p)+αCE(q,p)⋅T2
其中CE是交叉熵 (Cross-Entropy),
y
\mathrm{y}
y 是真实label, p是学生模型的预测结果,
α
\alpha
α 是蒸馏loss的权重。
这里要注意的是,因为学生模型要拟合教师模型的分布,所以在求p时的也要使用一样的参数T。另外,因为在求梯度时新的目标函数会导致梯度是以前的 1 / T 2 1/T^2 1/T2,所以要再乘上 T 2 T^2 T2,不然T变了的话hard label不减小 ( T = 1 ) (T=1) (T=1) ,但soft label会变。
3 常见的几种BERT蒸馏模型
3.1 BERT蒸馏
在BERT提出后,如何瘦身就成了一个重要分支。主流的方法主要有剪枝、蒸馏和量化。
量化的提升有限,因此免不了采用剪枝+蒸馏的融合方法来获取更好的效果。
接下来将介绍BERT蒸馏的主要发展脉络,从各个研究看来,蒸馏的提升一方面来源于从精调阶段蒸馏->预训练阶段蒸馏,另一方面则来源于蒸馏最后一层知识->蒸馏隐层知识->蒸馏注意力矩阵。
3.2 Distiled BiLSTM
来源:https://arxiv.org/pdf/1903.12136.pdf
作者在2019年提出,把BERT-large蒸馏到了单层的BiLSTM中,参数量减少了100倍,速度提升了15倍。

- 教师模型:精调过的BERT-large
- 学生模型:BiLSTM+ReLU
- 目标函数:
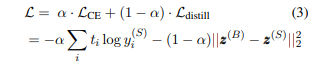
- 数据增强:采用规则进行10+数据增强
- 用[MASK]随机替换单词
- 基于POS标签替换单词
- 从样本中随机取出n-gram作为新的样本
3.2 BERT-PKD(2019)——精调阶段的蒸馏
既然BERT有那么多层,是不是可以蒸馏中间层的知识,让学生模型更好地拟合呢?
BERT-PKD不同于之前的研究,提出了Patient Knowledge Distillation,即从教师模型的中间层提取知识,避免在蒸馏最后一层时拟合过快的现象(有过拟合的风险)。

教师模型:精调后的bert-base
学生模型:6/3层 transformer
3.3 DistilBERT(hugging face2019)——预训练阶段蒸馏
来源:https://arxiv.org/pdf/1910.01108.pdf
之前的工作都是对精调后的BERT进行蒸馏,学生模型学到的都是任务相关的知识。HuggingFace则提出了DistillBERT,在预训练阶段进行蒸馏。
- 效果:参数减小了40%,速度提升60%,表现为教师模型的97%。
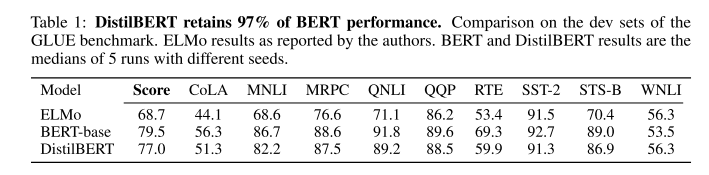
- 教师模型:预训练的BERT-base
- 学生模型:6层transformer
3.4 TinyBERT(HW,2019)——两阶段蒸馏
既然精调阶段、预训练阶段都分别被蒸馏过了,理论上两步联合起来的效果可能会更好。
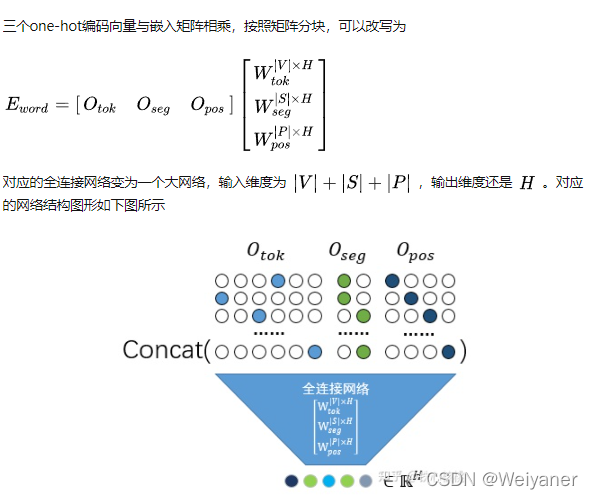
TinyBERT就提出了two-stage learning框架,分别在预训练和精调阶段蒸馏教师模型,其中,通用蒸馏可以帮助 student TinyBERT 学习到 teacher BERT 中嵌入的丰富知识,对于提升 TinyBERT 的泛化能力至关重要。特定于任务的蒸馏赋予 student 模型特定于任务的知识。这种两段式蒸馏可以缩小 teacher 和 student 模型之间的差距。

1 通用蒸馏
在通用蒸馏中,研究者使用原始 BERT 作为 teacher 模型,而且不对其进行微调,利用大规模文本语料库作为学习数据。通过在通用领域文本上执行 Transformer 蒸馏,他们获取了一个通用 TinyBERT,可以针对下游任务进行微调。然而,由于隐藏/嵌入层大小及层数显著降低,通用 TinyBERT 的表现不如 BERT。
2 针对特定任务的蒸馏
研究者提出通过针对特定任务的蒸馏来获得有竞争力的微调 TinyBERT 模型。而在蒸馏过程中,他们在针对特定任务的增强数据集上重新执行了提出的 Transformer 蒸馏(结构图如下)。

具体而言,精调的 BERT 用作 teacher 模型,并提出以数据增强方法来扩展针对特定任务的训练集。
此外,上述两个学习阶段是相辅相成的:通用蒸馏为针对特定任务的蒸馏提供良好的初始化,而针对特定任务的蒸馏通过专注于学习针对特定任务的知识来进一步提升 TinyBERT 的效果。
-
效果:参数量减少7.5倍,速度提升9.4倍的4层BERT,效果可以达到教师模型的96.8%,同时这种方法训出的6层模型甚至接近BERT-base,超过了BERT-PKD和DistillBERT。
-
教师模型:bert-base
-
学生模型:4/6层transformer
3.5 MobileBERT(ACL2020)
前文介绍的模型都是层次剪枝+蒸馏的操作,MobileBERT则致力于减少每层的维度,在保留24层的情况下
- 效果:减少了4.3倍的参数,速度提升5.5倍,在GLUE上平均只比BERT-base低了0.6个点,好于TinyBERT和DistillBERT。
MobileBERT压缩维度的主要思想在于bottleneck机制,如下图所示:

其中a是标准的BERT,b是加入bottleneck的BERT-large,作为教师模型,c是加入bottleneck的学生模型。Bottleneck的原理是在transformer的输入输出各加入一个线性层,实现维度的缩放。对于教师模型,embedding的维度是512,进入transformer后扩大为1024,而学生模型则是从512缩小至128,使得参数量骤减。
MobileBERT的蒸馏中,作者先用b的结构预训练一个BERT-large,再蒸馏到24层学生模型中。蒸馏的loss有多个:
- Feature Map Transfer:隐层的MSE
- Attention Transfer:注意力矩阵的KL散度
- Pre-training Distillation